Speech Transcription Server
Overview
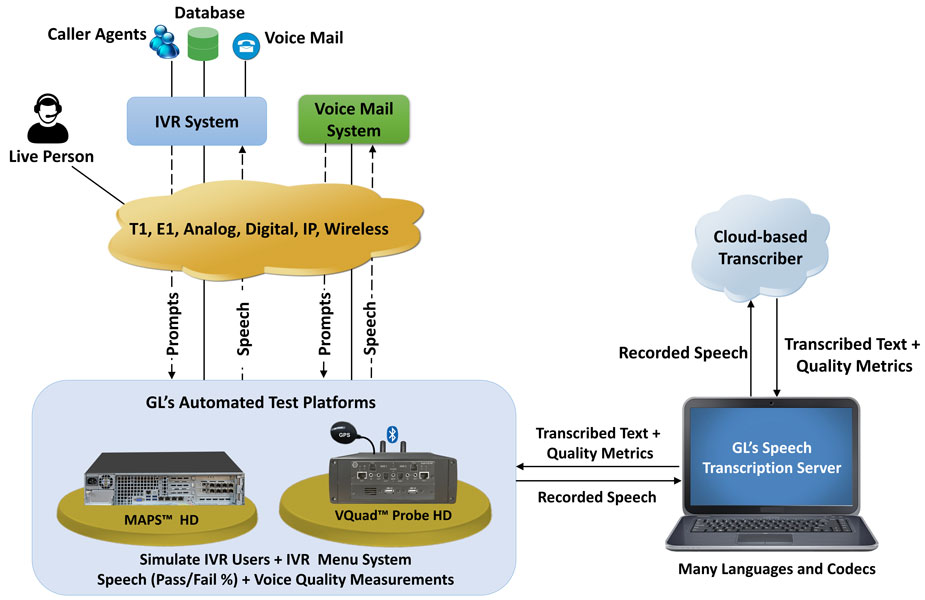
GL’s Speech Transcription Server (STS) is a PC-based automated Speech-to-Text conversion application. Among numerous applications, the Speech Transcription Server can be used for confirming voice prompts (announcements) and aid testing Interactive Voice Response (IVR) systems as well as voice transportation over any network. Network providers use the application to record the voice prompts associated with the IVR, perform a Speech to Text conversion on the recording to confirm the prompt was proper (based on what the prompt should be), and thus confirming their IVR functioning. The application can be used to verify network quality as well as effect of different codecs on the speech quality.
The STS utility includes a text-to-speech feature that allows automated, on-the-fly generation of audio files from user-defined text. The speech synthesizer provides options to configure languages (over 50 supported) and save audio files in PCM/WAV format. Text can be manually entered to generate voice prompts in the selected audio file format. The converted audio files are automatically saved in the specified directory path.
The STS utility supports the speech-to-text feature, enabling seamless conversion of recorded audio into text. It supports formats such as PCM, WAV, and GLW, ensuring high transcription accuracy with confidence scores ranging from 0 to 1. This functionality also processes audio in real-time and stores results for future analysis or use.
This application works with GL’s Audio File Conversion Utility which supports various industry standard codecs. This application can be good companion for GL's MAPS™, and VQuad™ applications that allow transmission and recording of voice to/from audio files over many industry standards telecommunication networks such as VoLTE, UMTS, GSM, FXO, FXS, 4-Wire, ISDN, SS7, etc.
By incorporating GL’s Speech Transcription Server, MAPS™ IVR allows users to automate precise IVR tree traversal configurations through MAPS™ profiles and test for pass/fail conditions. IVR menus are divided into configurable prompts where certain keywords are expected. MAPS record each prompt for speech-to-text transcription and analyzes the transcribed text.
The Speech-to-Text application can also supplement GL's Voice Quality Testing solution providing a more passive method to verify good quality audio. Using the VQT intrusive method for Voice Quality, the customer needs to send a pre-defined voice sample from near to far-side, record at the far-side and analyze based on the file sent from near-side. This is a very accurate method for generating a Voice Quality measurement but requires equipment at both ends of the call.
Alternatively, if access to both sides of the call is not available, the Speech-to-Text method can simply record a pre-specified sentence at the far-end and provide a Certainty score of the recorded Text based on what was expected. The Speech to Text conversion can confirm if the received audio, for instance a customer speaking into their phone, matches what was expected which would confirm there was relatively good audio on the network.
Main Features
- Ability to convert PCM or WAV or GLW files into text format
- Monitor single or multiple folders containing audio files for automatic transcription
- Each monitored folder can be configured for language and audio format
- Full automation using VQuad™ scripting
- Transcribe up-to 30 seconds of speech files into text
- Provides options to transcribe speech to text manually for a single PCM or WAV or GLW file using Manual Transcription option
- Accurate analysis of transcribed text with quality (Pass/Fail) scores
- Transcribe recorded short speech files into text; there is a maximum limit of 30 seconds for any single utterance
- Cloud-based processing provides accurate translations
- Concurrent transcription of up to 30 voice files
- Supports multi-languages such as U.S./U.K. English, French, German, Italian, Japanese and more
- Easy to access transcribed text via file, API or database
- Base Software includes up to 420 hours of audio transcription per year validity can be extended with annual support contract
- REST API support for transcription request and transcript retrieval
- Automated on-the-fly generation of audio files from user-defined text
- Ability to convert text files into PCM (u-law, a-law, PCM16-8 kHz, PCM16-16 kHz, PCM16-48 kHz) or WAV (u-law, a-law, WAV16-8 kHz, WAV16-16 kHz, WAV16-48 kHz) speech file formats
Working Principle
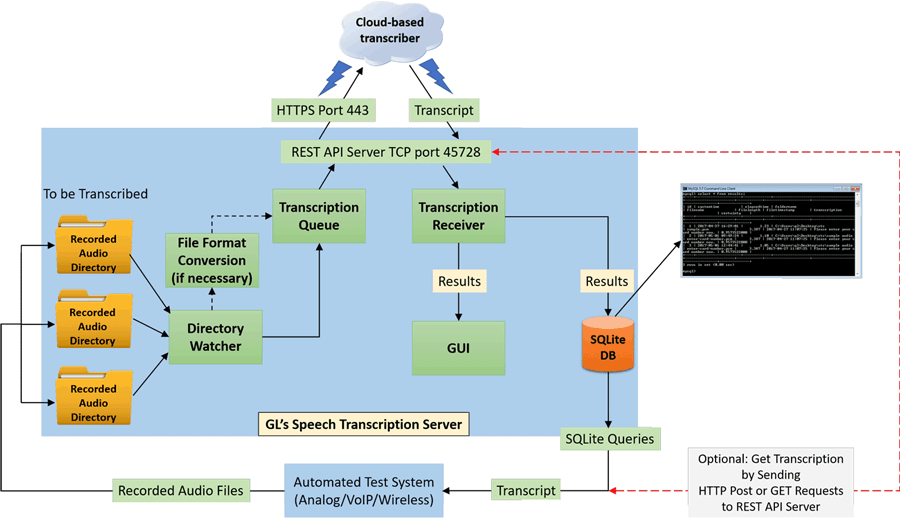
The Speech Transcription Server can convert recorded audio (*.PCM or *.WAV or *.PCM) files into text format. Single or Multiple folders are monitored continuously for short audio files and once the files are detected, they are placed in the speech transcription queue for transcription. These files are sent to the cloud-based transcription service and are accurately converted to text.
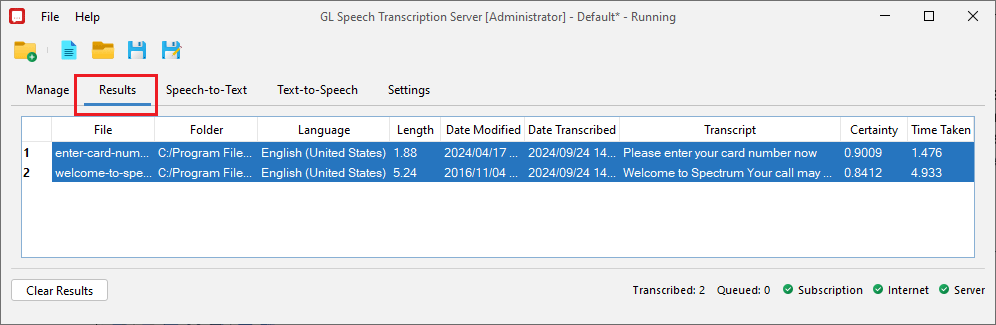
Transcription Results
Results are listed in the order they are transcribed and includes source file information (such as File Name, Directory path, Language, File length, Modified Date and Time) along with the transcribed file information such as Transcribed Date and Time, Transcription output text, Certainty score, and the Time taken in seconds to transcribe the file. The certainty ranges from 0-1 where 0 indicating the lowest confidence score and 1 indicating the highest confidence score for the transcribed text.
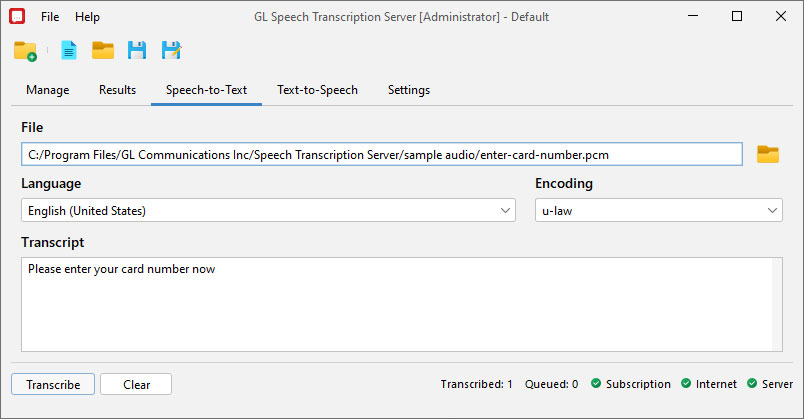
Speech to Text
STS software includes a Speech-to-Text Utility that automatically converts recorded speech into text. It supports various audio formats like PCM, WAV, or GLW, making it suitable for verifying voice prompts and assisting in IVR systems. The utility provides transcription accuracy with a confidence score, ranging from 0 to 1. Additionally, it can process audio in real-time and store results for analysis or further use.
Text to Speech
STS utility is enhanced with text-to-speech feature that allows automated on-the-fly generation of audio files from user-defined text. The speech synthesizer provides options to configure the languages (more than 50 languages are supported) and save audio files in pcm/wav format. Text can be manually entered to generate the voice prompts in the selected audio file format. The converted audio files are automatically saved in the specified directory path.
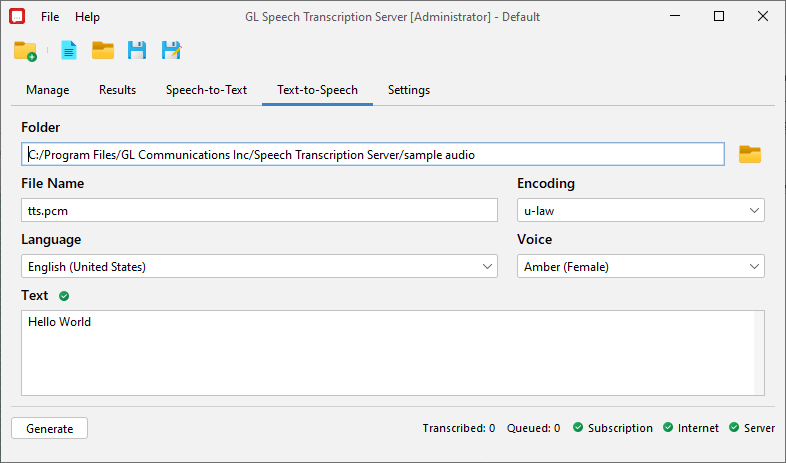
Generation of Audio Files from User-defined Text
REST Server
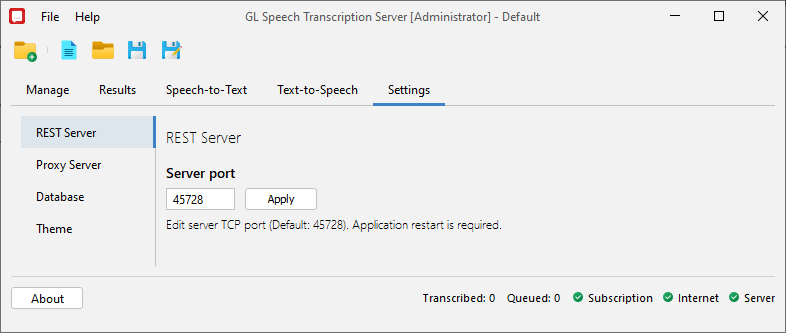
REST Server helps to transcribe and get the transcribed results on the remote PC using HTTP request on the configured REST API port number. REST server allows one speech transcription server instance to serve multiple clients. It allows the utility to be used with other GL’s intrusive test tools such as MAPS™ and VQuad™. One can send and receive transcription requests, as well as retrieve transcription results from database. Supports fast and easy integration with third party testing platforms.
Resources
| Item No. | Item Description |
VQT009 |
Speech-to-Text Conversion |
|
Related Hardware |
|---|---|
MAPS™ APS 24 Port |
DP005B - Rackmount PC, 1U 19", Xeon – Standard |
MAPS™ APS 48 Port |
DP005B - Rackmount PC, 1U 19", Xeon – Standard |
MAPS™ APS 96 Port |
SA005r - Rackmount PC, 2U 19", Xeon – Standard |
MAPS™ APS 192 Port |
SA005r- Rackmount PC, 2U 19", Xeon – Standard |
MAPS™ ALS 48 Port |
SA005r - Rackmount PC, 2U 19", Xeon – Standard |
MAPS™ ALS 96 Port |
SA005r - Rackmount PC, 2U 19", Xeon – Standard |
| Related Software | |
VQT002 |
Voice Quality Testing (PESQ only) |
VQT006 |
VQT w/ POLQA server licenses |
| VQT014 | AutoVQT™ (POLQA v2.4) |
| VQT014U | Upgrade from VQT POLQA to AutoVQT™ |
VQT010 |
VQuad™ (Automated File Transceiver Base Software) |
VQT013 |
VQuad™ with SIP (VoIP) Call Control |
VQT252 |
Dual UTA HD – Bluetooth Option |
VQT461 |
Dual UTA HD Smartphone ACC Cable |
PKS102 |
RTP Soft Core for RTP Traffic Generation |
PKS120 |
MAPS™ SIP |
PKS108 |
RTP Voice Quality Measurements |
* Specifications are subject to change without notice.
| Brochures |
|---|
| Speech Transcription Server Brochure |
| Presentations |
|---|
| Speech Transcription Server Presentation |